


Cultural Content: Content Audits
Part of the DIY Discovery Series

👋 Welcome
Today I’m talking about Content Audits
What’s a content audit?
A content audit is a data visualiser (generally a spreadsheet) that maps every page of your site against certain key metrics.
This article looks at content auditing in the context of beginning a web discovery phase. ‘Web discovery’ is a fancy phrase for the research you do in advance of/ to inform a new website build. (This article will form part of a wider series looking at all the tools and processes that will help along the way if you’re DIY-ing your own website discovery).
We’ll look at:
What the point of a content audit is
How to create one
What fields you might want to include
Skip to the end for an example content audit structure.
Here goes…
What’s the point of a content audit?
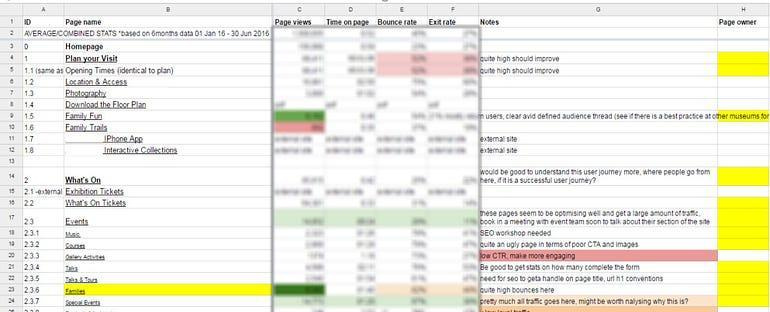
As mentioned above, a content audit lays out all the pages of your site section by section and set against a series of metrics.
The point of a content audit at the start of web discovery project is to give you a blueprint of the site as a whole – its structure and the patterns of user behaviour in different site sections. Done well, the audit should be able to raise ‘red flags’. It can isolate sections that are very baggy – loads of pages that no one is looking at; and also sections that are too sparse – lots of traffic to these pages but not enough content, or onward links, to develop that user journey. This helps give a sense of where the time will be spent in the project; both in terms of building up new content, and where there might be low-hanging fruit in deleting swathes of content that does not meet a user need.
You can put what data you want in these columns along the top. I tend to keep mine fairly simple and look at things like hits in a 12-month window and average engagement rate.
Skip to the end for a rationale for all the fields I’d use and a handy template content audit.
Seeing the wood for the trees
I differ from some of the published guidance on content audits in the sector. It’s tempting to keep adding more and more fields to your content audit, to try and make it more and more objection-proof.
But in the process, you end up with a pretty cumbersome document. Most of the time this document needs to be updated manually, which creates an increasingly large overhead the more fields you add. Having more fields doesn’t help to see the wood for the trees about which pages are performing well or less well relative to their position in the Information Architecture (IA).
Content audit as index, not encyclopaedia
I think it’s a mistake to try and make the content audit that kicks off a web transformation process an encyclopaedia. Inevitably, as you get further into the content design process you’re going to need to do more section-specific audits. But the metrics you’d want to choose to investigate – for example – the performance of an editorial section will be very different to a donate pathway.
This first content audit should just give you an index of pages, performance and owners. Down the line, you can do deep dives into SEO, reading scores, and whether your images have metadata, but to do this for every page of the site at this stage doesn’t seem helpful.
Manual vs scripted content auditing
How you do a content audit depends on the size of the site. You can do an audit manually, row by row, entering the fields for each page. Or you can create a scripted content audit (you’ll probably need some dev assistance for this option). This method allows you to export the fields you're after from other data sources and dynamically produce the content audit with the requisite fields.
The dynamic method sounds nicer, but partly because it avoids you getting your hands dirty in the nitty-gritty of the content and the patterns of behaviour between different site sections. It’s slow and mechanical, but getting your hands dirty and doing a manual content audit is the best way of getting to know the shape of your content and building up a picture of where to concentrate your energy. All the frustration you feel at going through low-performing pages is very useful when it comes to culling content that isn’t working and making better content.
However, for some sites, a purely manual approach is unrealistic. Here’s Kristina Halvorson and Melissa Rach’s take, from Content Strategy for the Web:
If you have less than 5,000 pages/pieces of content, you should probably look at all of it.’
(Halvorson and Rach, 2012, 59)
If your site is over 5,000 pages then a different approach is needed. In this scenario, you’re going to want to create a content sampling methodology to allow you to review certain sections manually. You’re going to want to cover content across different sections and with different levels of performance. This isn’t the scenario for most GLAM organisations so I’m not going to dwell here. (Halvorson & Rach have some helpful pointers p.59ff of Content Strategy for the Web).
Content audit fields - what to include
As described above, my initial content audit is quite high level. This helps me understand the current site architecture and isolate where patterns of audience behaviour are doing particularly good or strange things.
Here’s a free template / example of it

Page identifiers:
ID of the page, structured as 1.1, 1.1.1. This helps visualise the different site sections and their relationship to one another. Each top-level navigation item will have a new number.
So in the screenshot above, Plan Your Visit and What’s On have an ID of 1 and 2 as these are both top-line navigation items. A child page of Plan Your Visit, like ‘Location’, will be 1.1. A child page of Location would be 1.1.1.
URL – the unique identifier.
Performance metrics:
Pageviews of each page in a 12-month window – No quantitative metric is going to tell you the full story of a page. But it’s useful to flag pages (or entire site sections) that are getting very little traffic, as this indicates this content could be more effective, it’s a ‘red flag’ that wants more investigation, which is all you’re trying to establish with the initial content audit.
An engagement metric – These days I tend to opt for the GA4 metrics ‘average engaged time’ and ‘average engagement rate’.
It’s still worth bearing in mind that average engagement time will tend to be lower on a landing page than on a detail page. The purpose of a landing page is to convert users to a detail page, so time on page should be small if signposting is clear and direct. So not all ‘low’ engaged time metrics are necessarily a red flag.
Workflow / governance metrics:
Last updated – This can be useful – in conjunction with other metrics – as another potential red flag. Some pages (like articles on parts of the collection) may not need updating but continue to perform very well. But, if pageviews are low and the page was last updated years ago, this might warrant further investigation and potentially make a case for deletion / re-envisaging.
Page/information owner – It’s useful to get a sense of who created this content initially, and who’s maintaining it now. Which department’s expertise does it draw on? This can help you map the follow-up chats you’ll want to do based on the findings of the audit.
Notes:
A notes column allows you to start annotating thoughts/observations from your analysis. You can qualify these thoughts by taking a look at the webpage and in your follow up chats with information owners.
As you get further into the web transformation process you might use this initial audit to also map things like:
Status: reviewed / no change required / change required / move to unpublish the page
SEO metrics
User stories / user needs for a given page
Template type; depending on roles and responsibilities, it might be important for you to have a technical handle on how pages / components are moving and where gaps need to be filled
This article is Part 1 of a wider ‘DIY Web Discovery’ series. This series is designed to take you through the tools and processes you might want to consider if you’re leading the research to inform your new website. It’s not rocket science, but there are methods and best practices which can make your efforts much more effective.
The series is based on techniques I learnt whilst working for the Government Digital Service’s (GDS) Content Design team but then had the chance to employ and modify for myself when working for large museum organisations.
Subsequent posts will look at:
Stakeholder interviews
User research (user interviews and testing, personas, surveys)
Planning and testing a new Information Architecture (IA) and site navigation
Getting buy-in and content-design alignment
It’d be great to hear from other’s experiences working as GLAM content designers – it’s a field that lends itself to shared approaches and inter-organisation collaboration / shared standards, but that doesn’t exist in the sector yet - holler if you’d be keen for it.
Cheers, Georgina
Georgina@onefurther.com
This was *exactly* what I needed today!